[KEPCO] Constructing Demo System for AI based Diagnosis_1
Goal
To construct a demo test environment of KEPCO(Korea Electric Power Corporation) SEDA(Substation Equipment Diagnostic & Analysis) system using Oracle, Docker, Python, Flask, Gunicorn, and Nginx(HTML)
Oracle, Docker, Python, Flask, Gunicorn and Nginx(HTML)를 활용한 한국전력공사의 송변전 예방진단시스템 데모 테스트 환경 구축
Background
KEPCO(Korea’s Electric Power Corporation) is a principle agent of T&D(Transmission and Distribution) industry, selling electricity supplied by power genertion companies. The market of electric power in Korea is managed not by private enterpries but by Korean government, and KEPCO is ranked as 2nd on global electricity utility companies by monopolize T&D industry. Thus, KEPCO possesses huge amount of industrial assets of T&D and SEDA(Substation Equipment Diagnositc & Analysis) system is a running business that integrate and centralize the management subjects which were each substations previously. Especially, this system is very important in that the web page of SEDA is coninuously used until present by workers of KEPCO.
한국전력공사는 발전사로부터 전기를 공급받아 사용자들에게 판매하는 T&D(Transmission and Distribution) 산업의 주체입니다. 한국은 전력시장이 민간이 아닌 한국전력공사 주도의 공공시장으로 형성되어 있으며, 따라서 한전은 글로벌 전력회사 2위(아시아 1위)에 위치할 정도로 규모가 거대합니다. 그만큼 한전이 관리하는 T&D분야의 산업설비는 그 양이 상당한데요, 각 사업소별로 관리되고 있던 이 산업설비들을 한전 중앙 서버로 군집하여 통합 관리하고자 하는 사업이 바로 SEDA(Substation Equipment Diagnostic & Analysis) 시스템 구축사업입니다. 특히 SEDA는 실제로 한국전력공사의 임직원들이 계속해서 사용하는 화면이기 때문에 중요합니다.
My company is taking charge of the task that develop an AI based health diagnosis solution for assets on T&D industry with interlocking it to main SEDA system. Unfortunately, it is impossible to shate the contents of AI based health diagnosis solution since it is confidential. Neverthless, the process of interlocking the system was very interesting, and I hope to share this experience.
제가 속한 회사는 이 사업에서 특히 AI기반 변전설비의 상태예방진단 알고리즘 및 UI를 개발하고 이를 SEDA 메인 홈페이지에 연동하는 업무를 담당하게 되었습니다. 알고리즘 개발은 보안사안으로 본 포스트에서 다룰 수 없지만, 그 시스템 연동과정에서 제법 유용한 경험을 할 수 있었어서 이를 공유해보고자 합니다.
Motivation
The simplified architecture of SEDA system is as follow. First, the data acquired from each substations is collected at DB server constructed at SEDA. The collected data is variously analyzed, and the results of the anaylsis are described on SEDA web page. In our point of view, we apporach to Oracle to get data, and diagnose the assests with AI algorithm. The results of AI based analysis and diagnosis are decribed on UI web page, and the UI web page is exported to SEDA web page using iframe (Simply, iframe is just a method that copy the other web page and load it.)
SEDA의 간소화된 큰 아키텍처는 아래와 같습니다. 먼저 각 변전소에서 올라오는 데이터는 SEDA에 구축된 DB서버(Oracle)에서 수합됩니다. 수합된 데이터는 다양한 분석 과정을 거치게 되고 이 분석 결과가 SEDA web page에 표현됩니다. 저희는 이 Oracle에 접근해서 변전설비의 여러 데이터를 획득하여 각 설비의 건전성 상태를 진단하고, 진단 및 분석 결과를 UI web page로 구현하여 이를 iframe형식으로 SEDA web pge에 표현합니다. (iframe은 쉽게 표현해 화면을 그대로 옮겨놓는 방식입니다.)
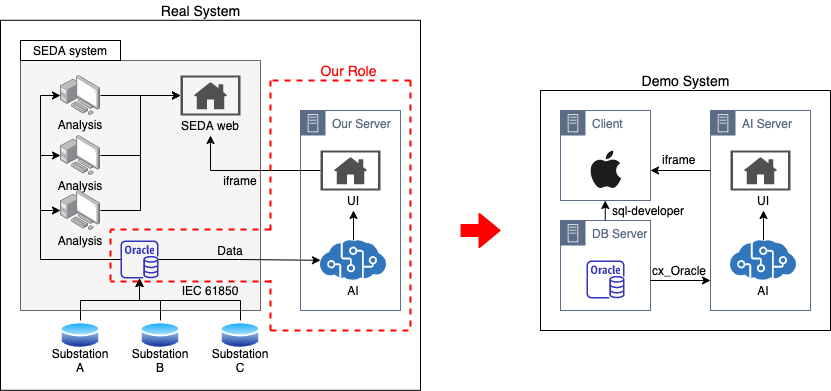
Of course, it is difficult to develop this service (“our server” on diagram) always at the server. The reasone is that KEPCO construct entire network connection as a closed network: it is impossible to connect the network remotely. Since it is cost-unefficient to always visit KEPCO and develop the service in the closed network, it is required to construct a demo system and import it after finishing development.
물론, 이러한 서비스(“our server” on diagram)의 구축을 해당 서버 붙어서 직접 작업하는 것은 한계가 있습니다. 특히 눈치채셨겠지만 보안상의 이유로 한국전력공사는 모든 환경을 내부 폐쇄망으로 구성하였기 때문에 원격으로 접근하는 것이 불가능합니다. 따라서 서버의 개발을 매번 폐쇄망에서 작업하는 것은 현실적으로 어렵기 때문에 저희는 데모 시스템을 구축하고, 그 데모시스템을 추후 폐쇄망에 이식해야만 합니다.
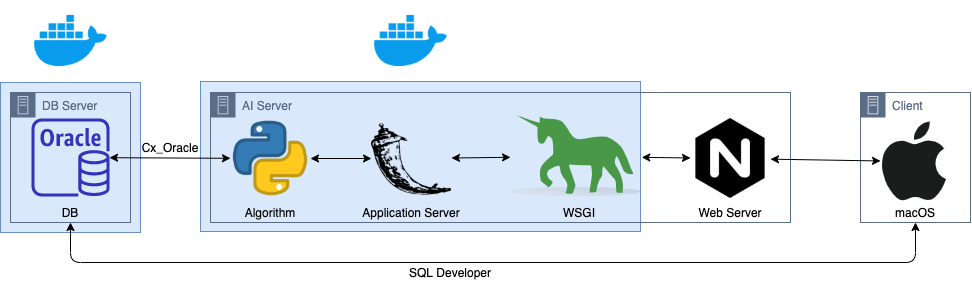
Finally, the demo systemt that would be constructed in this project is as above. The physical servers are three; DB server, AI server, and Client server. First, DB server contains SQL DB based on Oracle, and managed on Docker container. Second, AI server contains algorithms with python, an application server with Flask, a WSGI with gunicorn, and a web server with Nginx. Third, Clinent server use macOS.
최종적으로 구축하고자 하는 데모 시스템은 위와 같습니다. 먼저 물리적인 서버는 DB Server, AI Server, Client Server로 구성됩니다. DB 서버는 ‘Oracle’기반의 SQL DB로 이루어져 있고, 이는 도커상에서 관리됩니다. AI Server에서는 각각 알고리즘엔 ‘Python’, 어플리케이션 서버엔 ‘Flask’, WSGI는 ‘gunicorn’, 웹 서버로는 ‘Nginx’가 사용됩니다. 마지막으로 클라이언트 서버는 ‘macOS’를 가정했습니다.
Requirements
This project aims following targets.
본 프로젝트에서는 다음의 내용을 구현하는 것을 목표로 합니다.
- To construct
Oracleserver.- To import and export data from
Oracleserver to AI server usingPython.- To transfer the results of AI server using
Flask- To construct above requirements using
Docker
Used Language
This project uses followings.
본 프로젝트에는 다음을 사용됩니다.
DockerOraclePythonFlaskguinicornNginx
Systemt Specification
This project uses following HW resources.
본 프로젝트에 사용된 HW 리소스는 다음과 같습니다.
- Oracle Server: Linux (
Ubuntu 20.04)- AI Server: Linux (
Ubuntu 18.04)- Client Server: macOS (
Big sur) on M1 chip